引言
我们对于某一个技术的理解,往往是基于这个技术试图解决的问题。举例来说,人脸识别技术是为了解决个人身份的验证问题,有了人脸识别,解锁手机的时候不需要输入一长串密码,方便且简单。但复杂的是,一个技术通常不仅局限于解决一个问题,例如人脸识别还可以用来解决:如何打造一个可以精准定位每个公民行踪的社会监控系统。显然,如果我们用后面这样的问题来重新审视人脸识别,那我们对其理解也会有所区别,方便的代价往往是个人隐私的牺牲。与其说理解技术的关键在于提出不同的理论,不如说在于提出不同的问题。本文希望对人脸识别背后的机器学习技术提出另一种问题,试图从一条不同的路径来理解机器学习。机器学习(machine learning)作为人工智能的一个子领域,它利用统计和概率从大型数据集(dataset)中学习模式,然后对新输入的数据进行判断和预测。机器学习包含多种方法,用于解决不同的问题。其中,基于多层神经网络架构的深度学习(deep learning)是今天的主流技术范式,它在自然语言处理和多模态感知能力方面取得了突破性进展,常见应用如机器翻译、文本和图像分析和生成等等。
那么如果今天以机器学习为主流范式的人工智能是答案,它是在回答什么问题呢?我们熟悉的版本是:如何通过模拟生物智能来创造出比人类更聪明的机器。这个问题的提问背景需要追溯到 1956 年夏天的达特茅斯研讨会。大多数论述都认为达特茅斯研讨会是人工智能历史的起点,因为在研讨会提案中,约翰·麦卡锡(John McCarthy)第一次正式提出了“人工智能”这一概念。之所以提出人工智能,是因为他希望和诺伯特·维纳(Norbert Wiener)的控制论区分开,其目标不是人工的(artificial)智能,而是真正的(genuine)智能。在向洛克菲勒基金会递交的提案中,麦卡锡表明人类学习行为的每个方面,或者说是人类智能的特征,从原则上都可以被精准地描述,因此也就意味着可以制造一台机器来模拟。从这里看出来,在早期人工智能被提出的时候,其根本假设是人类智能可以被描述,同时可以被模拟,智能的关键在于学习。而这奠定了今天我们对于人工智能的理解:人工智能是通过将生物学上的智能机制嵌入计算机来实现的。
然而在实践性层面,人工智能研究者并不在意这些程序是否以人类的思维方式进行思考,而是希望创造出和人类一样,甚至超越人类的任务执行程序 (Mitchell, 2019, 页 24)。这背后便是另外一种提问方式的显影,即如何通过机器将人类劳动自动化?如果我们从这一角度发问,那么当前的机器学习便可以理解为劳动自动化的“最佳”实现形式。劳动自动化不是一个信息时代的新颖问题,这一愿景植根于机器智能发展的长远历史当中。
19 世纪,在殖民帝国扩张时期的英国,精准对数表(logarithmic tables)对于保持海上航线的方向至关重要,如果“计算机”出错,则会导致了巨大的商业损失。当时的“计算机”并不是指代机器,而是用来形容为政府、天文学会或者海军进行手工计算工作的人们,她们通常是女性办公室职员。由于计算项目的复杂和庞大,难免会出现计算错误、抄写错误或者印制错误。为了简化上述这一耗时同时也容易出错的工作,发明家查尔斯·巴贝奇(Charles Babbage)萌生了一个想法:利用蒸汽驱动的自动机器来取代手工计算的重复性工作。这个想法催生了现代计算机的先驱——差分机(Difference Engine)。巴贝奇所想象的不仅仅是一个计算设备,而是一个可以在工业规模上开展计算业务的计算引擎(Engine),“引擎”这个词背后反映的是对于无限性能和经济增长的渴望。而这种渴望的社会动因来自于政府努力推动的自动化计算项目。政府之所以这么做,一方面是因为商业目的,另一方面则是要确保英国在海上贸易的霸权地位 (Daston, 2018)。
除了发明机器,巴贝奇还从经济规划的角度提出了机器的劳动理论:机器模仿并取代以前的劳动分工。劳动分工的出现不仅是为了更好地将劳动力分散到模块化任务中,而且也是为了更精确地测量每项任务的成本。资本家将生产过程分散成小任务,每个工人只需专注于完成特定的任务,而不需要参与整个生产过程。在劳动分工的基础上,根据每个任务所需的劳动量来确定商品的价值,以确保最大化利润。巴贝奇将劳动计算原理应用到了脑力劳动,从而形成了自动化计算的基本理论。总之,当代意义上的自动计算机概念,产生于将文员的脑力劳动机械化的计划,而非古老的炼金术梦想——制造会思考的机器。长期以来,后一种说法经常被用来掩饰前一种 (Pasquinelli, 2023, 页 54)。从一开始,计算就不仅仅是一种工具,而是一种文化技术,它扮演着监督劳动和优化计算剩余价值的社会角色。另一方面,“为了让机器看起来聪明,有必要隐形它们的力量来源,即围绕和运行它们的劳动力” (Schaffer, 1994)。
如今的人工智能依旧继承着上述特征,只是随着算力的发展,复杂程度有了巨大差异,但本质并没有区别。基于大量社会资源和集体知识的机器学习可以理解为马克思所谓的“一般智力”的机械化和自动化。本文将机器学习的流水线分解成训练数据集、学习算法和统计模型三个部分,首先分析训练数据集中被隐匿的人工劳动,其次通过追溯神经网络的社会历史,以此来说明人工智能是由人类集体行为构成的一部感知自动化机器。
训练数据集:被隐匿的劳动
当你打开一个训练人工智能的图片数据库,你会看到成千上万张图片及其对应的标签。如果说机器学习算法是一份菜谱,那么训练数据集(training dataset)便是食材,只是这些数据是从何而来,而又是如何被贴上标签的呢?当我们更仔细查看,还会发现喝啤酒的年轻人被贴上“酒鬼、酗酒者”的标签,穿着比基尼微笑的女性则是“荡妇” (Crawford & Paglen, 2021)。人工智能这样的价值判断不是天然形成的,因为训练数据集从来都不是原始、独立和公正的,其选择倾向本身就带有着人类干预的意识形态,而不仅仅是一种技术构造。
构建一个数据集通常需要以下步骤:第一,产生数据的人类劳动;第二,将数据按照一定格式进行编码;第三,将数据按照一定的结构组织成数据集;最后,在监督学习中,对数据进行标签分类。以人工智能历史上最重要的图像训练集之一 ImageNet 为例。普林斯顿大学的计算机视觉教授李飞飞从乔治·米勒(George Miller)的 WordNet 英文单词数据库得到启发,WordNet 将单词按照同义词分组,并且按照最具体到最抽象的等级,进行结构排序,形成词汇链。而李飞飞的想法就是根据 WordNet 中的名词构建一个图像数据库,使得 WordNet 中的每个名词都和对应的图像相关联。李飞飞和她的合作者开始在 Flickr 和 Google 等平台检索 WordNet 中的单词,并下载数百万张免费图像。但在这过程中总是会遇到不相关的图片,繁重的筛选任务估计需要 90 年才能完成。结果,团队找到了亚马逊土耳其机器人(Amazon Mechanical Turk),将标注图像中物体的劳动外包给数十万名工人,而这些来自世界各地的匿名工人每项任务的报酬只有几美分 (Mitchell, 2019, 页 91)。
亚马逊土耳其机器人,这个奇怪的名字背后有一个故事。1770 年,匈牙利发明家 Wolfgang von Kempelen 发明了一台玩国际象棋的智能机器“土耳其机器人”,它的主要目的是讨好当时的奥地利皇后。近 90 年的时间里,“土耳其机器人”在欧洲各地的象棋比赛中都取得胜利。但真相却是一个骗局,“土耳其机器人”背后其实是一个象棋高手在秘密操控。而 160 多年后的 2005 年,亚马逊公司创建了众包平台亚马逊土耳其机器人,如今平台上有超过十万名“土耳其工人”,他们来自 100 多个国家,这些工人通过完成一系列称为 HIT 的快速任务来赚取小额收入。就像最初的土耳其机器人一样,用户可能会认为平台正在使用先进的人工智能程序来完成任务。但实际上,它只是一种“人工的”人工智能(artificial artificial intelligence),是由远程、分散和底薪的工人点击而驱动。在土耳其机器人的帮助下,短短两年内,就有超过 300 万张图像被标注上相应的 WordNet 中的名词,并组成了 ImageNet 数据集。很快,ImageNet 成为了计算机视觉领域非常重要的数据集,世界各地的实验室每年都会基于 ImageNet 举办年度竞赛,角逐哪种算法可以最精准地识别图像。在 2012 年的 ImageNet 大规模视觉识别竞赛中,一个名为 AlexNet 的程序脱颖而出,这个程序没有使用当时流行的计算机视觉算法,而是使用后来成为主流范式的卷积神经网络。当人们在为这当代人工智能发展的转折点欢呼雀跃的时候,和工业时代类似,为训练数据集提供动力的工人则被这机器奇观所掩盖了 (Aytes, 2012)。
包括 ImageNet 在内的机器学习数据集主要都起源于全球北方的高科技公司(Amazon Web Services、IBM、Microsoft、Google、Oracle、Appen 等),而这背后是人工智能的殖民产业链,一方面人工智能正在加大开采自然资源,同时也在产出大量的有害废品,这些过程的危害转移到了全球南方,而利润却流向了越来越富裕的西方经济体。表面收益中的绝大多数都会给边缘化社群、脆弱的生态系统和未来的人类带来威胁——而企业社会责任的言辞和指标却忽略了这些 (Dauvergne, 2022)。另一方面通过众包平台将如标记、筛选等数据脏活转移,进一步加剧不平等的国际数字劳动分工。
一个突出的例子是 OpenAI 与肯尼亚外包劳工公司 Sama 合作以减少 ChatGPT 上的有害内容。ChatGPT 的训练数据内容来自于互联网,一方面大量的数据使得 ChatGPT 的“文字接龙”功力进步飞快,另一方面数据中存在的暴力、性别歧视和种族主义言论也是 ChatGPT 的噩梦。而因为没有简单快速的方法来让数据中的“不雅之辞”消失,所以只有通过构建额外的人工智能驱动的安全机制,OpenAI 才能控制这种危害,生产出适合日常使用的聊天机器人。为了构建这个安全系统,OpenAI 借鉴了 Facebook 等科技公司的做法:搭建能够检测仇恨言论等有毒语言的人工智能,以帮助平台进行言论筛查。实现起来并不复杂,和深度学习的原理一样,只不过现在需要给人工智能提供的是充满暴力、仇恨言论和性虐待的语料了。只有这样才可以训练出一个能够检验“毒性语句”的模型。最后,OpenAI 再将该检测器内置于 ChatGPT 中,过滤掉令人不适的言论。而负责标记这些毒性语句的则是 Sama 公司在肯尼亚、乌干达和印度所雇佣的员工。Sama 将自己定位为一家“道德人工智能”公司,声称已帮助超过五万人摆脱贫困。而实际上,根据员工的表现,他们每小时能够拿到的税后工资只有 1.32 美元到 1.44 美元不等。相比之下,内罗毕接待员的最低工资为每小时 1.52 美元。更糟糕的是,从事数据标注工作的 Sama 工人每班工作 9 小时,审查暴力、有毒和辱骂性内容,这些内容来自互联网最阴暗的角落,充斥儿童性虐待、兽交、谋杀、自杀、自残和酷刑等可怕的细节,给工人们的精神带来了巨大创伤 (Perrigo, 2023)。
硅谷科技行业善于营造一尘不染的门面,那是因为数据密集型劳动都是在距离硅谷千里之外的东非、印度、菲律宾和肯尼亚的难民营里完成的。通过隐匿人类在数据工作中的辛劳,算法和模型的“超能力”便大放异彩,而实际上,机器学习神话背后都是那些不被看见的汗水与眼泪。
学习算法:感知自动化的社会起源
就像上一节所说的,机器学习算法就像是一份菜谱,它代表着处理数据的不同规则。而运行机器学习算法的过程中不可避免地存在着算法偏见,人工智能公司致力于寻找最简单和快速的算法来利用数据,这同时也威胁着文化多样性和民主 (O’Neil, 2016)。如果我们对机器学习历史的第一个算法进行简单考古,便可以发现这种偏见的社会起源。机器学习的第一个算法需要从一场争论开始讲起。人类的感知是否是一种认知行为,是否可以被分析和表述,从而被机械化,这一问题一直是人工神经网络的核心。
在 20 世纪 40 年代梅西会议期间,控制论学派认为感知作为一个整体,可以由机器来计算。格式塔学派则认为机器永远无法模仿人类大脑中复杂的合成能力。为了回应格式塔学派的观点,神经生理学家麦卡洛克(Warren McCulloch)和数学家皮茨(Walter Pitts)在 1943 年发表了一篇论文《神经活动内在思想的逻辑演算》,证明了可以使用逻辑演算描述神经网络的运行机理,提出了“人工神经网络”的概念。他们认为这种网络可以类似于人脑神经元一样,使用逻辑推理进行工作,就像我们解决数学问题一样 (McCulloch & Pitts, 1943)。
在 1947 年,他们发表了另一篇关键论文《我们如何认识普遍性;对听觉和视觉形式的感知》,探讨了如何让计算机识别和理解视听形式。论文关注的是识别二维矩阵中的模式。这个识别装置由感光器组成,它可以将视觉输入转换为数字图像,也就是一组由数值表示的像素网格。不考虑颜色,网格将黑色像素的值编码为 1,白色像素的值为 0。模式识别装置会将大量输入计算解析为二进制输出 1(真),或者 0(假)(Pitts & McCulloch, 1947)。简单来说,模式识别装置能对同一类模式的任何输入,计算出相同的输出。以此来挑战格式塔学派对人类认知独特性的信念,并证明感知可以用算法描述和自动化。更关键的是,两篇论文之间的转变是一种认识论上的转变:1943 年的论文提出了神经网络作为推理机器来处理演绎逻辑问题,而 1947 年的论文则指向了用于自动识别模式的归纳机器。前者是演绎逻辑,后者是归纳逻辑。这一转向也为当代意义上的机器学习铺平了道路。
卡洛克和皮茨的研究启发了第一个人工神经网络的发明。20 世纪 50 年代心理学家弗兰克·罗森布拉特(Frank Rosenblatt)发明了感知机(Perceptron)。1957 年,感知机首次在 IBM 704 上运行。在最早的测试中,在计算机中输入一系列打孔卡片,经过 50 次试验过后,学会了区分左右侧标记的卡片。罗森布拉特认为这一成功证明了可以设计更复杂的感知机结构以识别更复杂的图案。1960 年,Mark I 诞生了。Mark I 感知机实现了一个由三层单元组成的简单神经网络,单元之间依次连接:感觉、联想、反应。输入层(也称为视网膜)是一个 20×20 像素的摄像头,共有 400 个感光器。这些感觉单元以固定权重连接到由 512 个联想单元组成的层上。联想单元本身又与 8 个反应单元相连,其权重可自动调整。联想和反应单元根据阈值来工作的:它们将输入值相加,只有当总和超过给定的阈值时才会启动 (Pasquinelli, 2023, 页 190)。
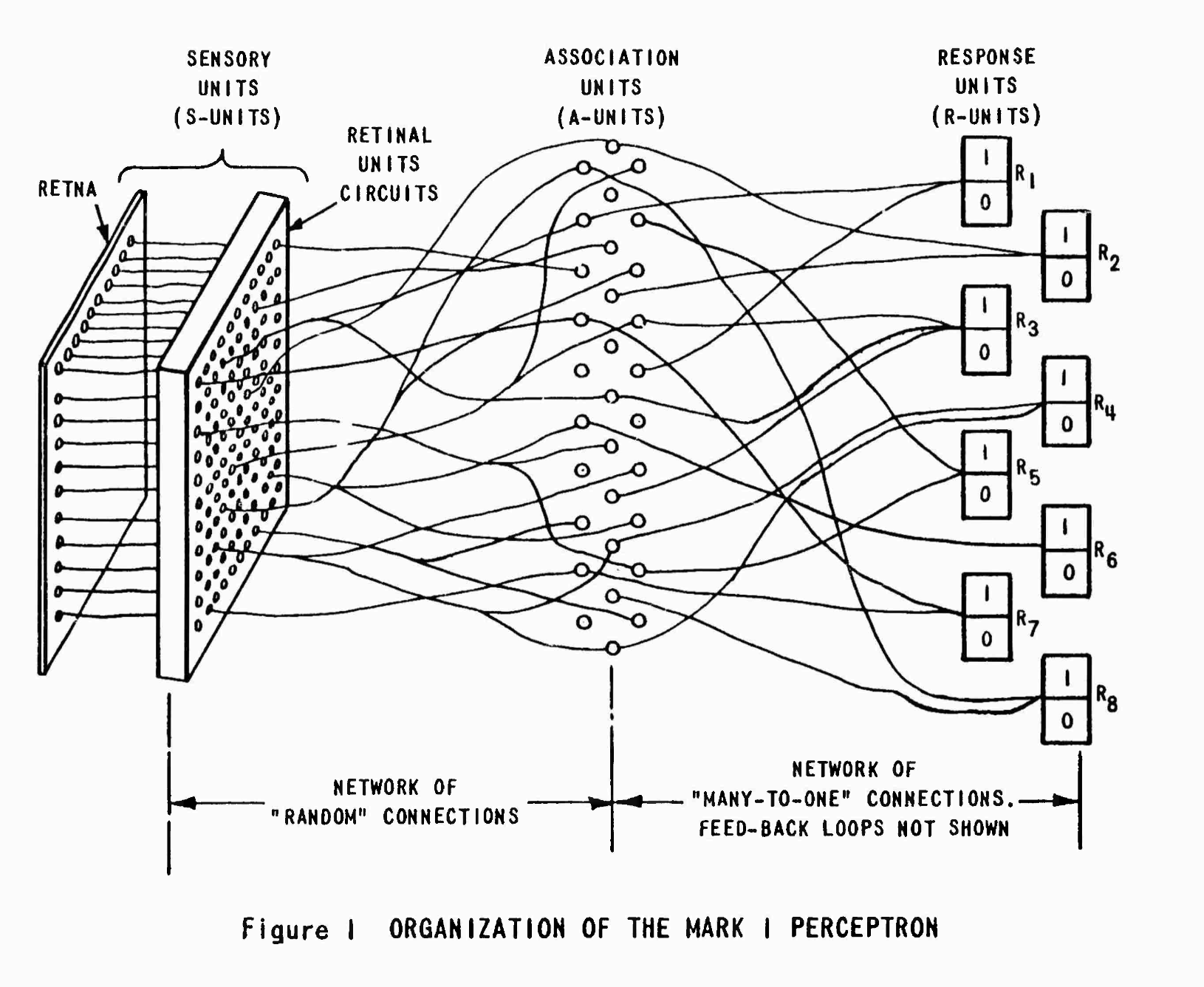
1958 年 11 月,英国国家物理实验室举行了人工智能首次国际研讨会,主题是思维过程的机械化 (National Physical Laboratory, 1959, 页 421–456)。罗森布拉特在会议上澄清了感知机背后的数学原理,即多维空间中数据的统计可分性定理(theorem of statistical separability of data in a multidimensional space)。这个抽象定理其实并不难理解。想象你面前有一个大盒子,里面装满了各种不同形状和颜色的气球。现在,你想要找到一种方法,可以用一条线在盒子中画出来,将气球分成两组,比如红色气球和蓝色气球。这就是所谓的多维空间中数据的统计可分性定理。在这个例子中,每个气球的形状、颜色和大小可以看作是一个维度,而我们要做的就是找到一种数学方法,可以在这些多维度的数据中找到一条线(或者平面、曲面等),将它们有效地分开成不同的组别。简单来说,通过统计学方法,我们可以在这个复杂的多维空间中找到规律和模式,从而实现数据的分类。换句话说,也就是为一个多参数的函数找到合适的参数。
然而残酷的是,这种多维投影的统计方法来源于 19 世纪后期心理测量学和优生绝育领域。1904 年,心理学家查尔斯·爱德华·斯皮尔曼(Charles Edward Spearman)提出了“智力”的统计测量——g 因子。g 因子代表了一种普遍存在于各种认知任务中的潜在认知能力。斯皮尔曼认为,不同的认知任务之间存在着一种共同的因素,即智力的核心要素,这个因素被称为 g 因子(general intelligence factor)。g 因子是一种超越具体任务的认知能力,它涵盖了人们在各种认知任务中所表现出的智力水平。斯皮尔曼通过统计分析发现,不同的认知任务之间存在着一定的相关性,人们在文学和语言上的表现,与在音乐上或数学上的表现之间存在关联,即在一个任务上表现出较高智力水平的人往往也在其他任务上表现较高。这种相关性表明了一个普遍存在的认知能力,即 g 因子。智力测试理论最骇人听闻的实践便是通过对父母进行智力筛选,可以有目的地让新一代人更聪明和健壮。在 20 世纪 30 年代,披着科学外衣的智力测试和纳粹式的优生学沆瀣一气,导致了美国境内有超过 6 万人因“智力低下”被施以强制绝育手术。
到了 20 世纪 50 年代,心理测量学成为美国大学心理学系中一个有影响力的子领域。它以量化和统计测量人格特质、认知能力和工作技能为主要目标。这一时期,许多学生开始将心理测试的数据转化为向量,以计算相似性、协方差和模式等。技术史学家乔纳森·佩恩(Jonathan Penn)追溯了罗森布拉特早期的职业生涯和研究轨迹,发现罗森布拉特在他的博士研究中已经使用了多维分析的心理测量技术,目的是研究人格特征。1953 年,罗森布拉特要求康奈尔大学的 200 名学生回答一个关于他们童年的问卷,使用数字来回答每个问题,接着再通过因子分析的方法分析结果,以计算每个问卷的数字矩阵之间的相似性。在罗森布拉特的研究中,他还尝试自动化统计分析,设计了一台名为电子个人分析计算机(EPAC)的计算机 (Penn, 2020)。这台计算机在心理测量学中常用的多维分析任务中取代了人类“计算机”,与巴贝奇将计算引擎取代人类计算机一样,可以说罗森布拉特将计算机取代了统计学家,从而塑造了今天所理解的机器学习。到了他的博士研究结束时,罗森布拉特注意到认知测试的数字矩阵看起来与数字图像的数字矩阵相同,并开始考虑将相同的多维分析技术应用于视觉模式识别。这让我们看到了另一种技术创新方式,即度量学先于自动化:罗森布拉特将用于量化认知任务的工具,以实现认知任务的自动化 (Pasquinelli, 2023, 页 202)。统计工具不仅成为心理学中“智力”的模型,也成为劳动力自动化发展中“人工智能”的模型。
然而,这种统计视角的发展也伴随着一些根深蒂固的问题。一方面心理测量学的起源与种族主义和优生主义的议程有关,旨在证明智力与种族之间的相关性。它被用来维持社会等级和种族隔离,并对劳动力进行规训。统计工具的广泛应用也导致了对智力的量化和标准化,将智力简化为可计量的对象。这种量化的智力观念在一定程度上支持了精英主义的社会秩序。从智力测试到优生绝育,再到灭绝人口的种族主义,从模式分类到图像识别,再到人脸追踪,技术的社会史重响,也同时解释了人工智能作为监控资本主义的应用继承路线 (Zuboff, 2019)。总之,第一个人工神经网络——感知机——并非作为逻辑推理的自动化而诞生,而是起源于最初用于衡量认知任务中的智力并据此组织社会等级的统计方法,它的目的是试图创造出资本主义所欲望的“没有人的头脑” (Penn, 2023)。
统计模型:自动化的自动化
当训练数据集被输入到学习算法中,学习算法会输出一个模型。模型包含从输入数据中学到的模式或关系。然后,该模型可用于分析新数据。而在训练机器学习模型的过程中,由于每个模型都需要一组不同的超参数,为了确定最佳的超参数组合,需要进行多次实验,这个过程也称作超参数调优(hyperparameter tuning)。机器学习作为一种自动化劳动的技术,那么,调试机器学习模型本身作为一种劳动是否也可以被自动化呢?自动化机器学习(AutoML)作为一种“自动化的自动化”技术,实现了新一层的递归,其目标不是从数据中生成一个模型,而是生成一个能够优化机器学习模型训练的模型。
佩德罗·多明戈斯(Pedro Domingos)将机器学习的终极递归能力想象成为“主算法”,这是一种假想的学习算法,如果给它适当的数据,它可以从中学习任何东西,简单来说,主算法可以生成解决任何问题的模型,它不仅能够模拟任何其它机器,还能够自动生成任何机器 (Domingos, 2015)。我们很容易理解资本主义会如何拥抱这种自动化劳动过程的终极机器,事实上,AutoML 也确实是由科技巨头在推动,当然表面上的包装依旧是美好的技术民主化外壳,美其名曰:“构建人工智能很难,所以科技巨头正在构建能够自动构建人工智能的人工智能。通过迫使计算机承担更多繁重的工作,世界上最大的科技公司正在加快人工智能进入日常生活的速度”,这听起来似乎善意满满,但其实是因为 Facebook 的广告团队中工程师感受到了更大的压力,需要改善公司的广告定位,以便更精确地推送广告。如此一来,建立一条所有工程师都可以使用的机器学习装配线便显得迫切和重要了 (Metz, 2016)。科技巨头们开发了“一键式”和“端到端”的 AutoML 软件包,包括 Facebook 的 FBLearner Flow、Uber 的 Michelangelo ML 和百度的 EZDL。这些产品旨在将整个机器学习的劳动过程简化为一个用户友好型应用程序,强调零门槛开发,也就意味把自动化技术的“最后一公里路”修到每个程序员的屏幕面前。
另外人工智能在过去十年中取得显著进步,主要得益于上述提到的数据集的扩大以及学习算法的进步,这也促使了大模型例如 OpenAI 的 GPT-4 和谷歌的 Bard 的出现,它们也被称为基础模型,这是因为它们拥有庞大的基础预训练数据集,可以灵活地针对各种任务进行微调(finetune)(Bommasani 等, 2022)。从技术角度来看,大模型并不新鲜——它们依旧是基于深度神经网络和自我监督学习,这两者都已经存在了几十年。然而,过去几年基础模型的规模和范围已经超出了我们对可能性的想象。例如,GPT-4 拥有 1.8 万亿个参数。这使得如今的机器学习模型更趋向于一种自适应技术,同一个模型可以进行翻译,同时也可以用于图像描述。大模型在庞大的数据集上训练单一的深度学习算法,并将其用于自动化下游任务:问题解答、情感分析、信息提取、文本生成、图像生成、视频生成、风格转换、对象识别和指令跟踪等等 (Pasquinelli, 2023, 页 223)。当社会中的集体行为以及集体知识都成为了训练数据集收集的对象,并且经由算法生成模型和个体互动,机器学习作为一个装置就像柏拉图“洞穴隐喻”之上的另一洞穴,其“看”世界所使用的镜头本身就内含着对真相的多层次压缩和扭曲,使得世界趋向于向量化而不是多元化,用统计生成的幻觉来取代我们对因果关系的认识。
结语
自动化是一个神话,自动化的自动化也同样是,因为如果没有人类集体知识、文化遗产和各种类型的劳动形式,当今的人工智能都无法实现。另外需要正视机器学习的一点是,即使最先进的人工智能系统在完成某些特定细分领域的任务拥有和人类相当、甚至超越人类的能力,但这些系统都缺乏人类在感知意义的能力,主要表现在:非人类式的错误、难以对学习到的知识进行跨领域的迁移、面对攻击时候的脆弱性以及对于常识的缺乏。总之,目前的人工智能依旧没有打破通向意义的障碍 (Malik, 2020; Mitchell, 2019, 页 251)。意义依旧掌握在人类主体的手中,而如果我们希望重新设计人工智能 (Acemoglu, 2021),同样也需要依靠人类主体的有意义参与,“有意义”则代表着拥有说“不”的权利。重新发展一种去连结主义(de-connectionism),集体决定使用哪些数据、哪些算法、为了哪些人、达到哪些目的。